Comment fonctionne ChatGPT ?
Cette question, de plus en plus de personnes se la posent. À la fois des jeunes chercheurs, des ingénieurs, mais aussi le grand public. Cette page est une tentative d’expliquer ce que je comprends de cette fameuse IA.
Selon vos connaissances en informatique et le niveau de détail que vous cherchez, la réponse que vous attendez est complètement différente.
C’est pour cette raison que je vais détailler le fonctionnement de chatGPT en plusieurs parties: l’idée, l’historique, le mécanisme, l’entrainement et les mystères. Chaque partie a des prérequis différents, n’hésitez pas à sauter les parties qui ne vous intéressent pas.
L’idée
prérequis: aucun
Partons du fonctionnement de votre cerveau. Vous êtes en pleine discussion, et une phrase se forme dans votre cerveau. Vous êtes fatigué, si bien que les mots qui sortent de votre bouche se forment de manière presque automatique. Vous pouvez même faire l’experience dès à présent: partez d’un mot, puis formez une phrase en ajoutant des mots un par un, ceci de plus en plus vite.
Que fait votre cerveau à ce moment ? Comment est-ce possible que votre cerveau forme des phrases relativement cohérentes de manière presque automatique ?
La réponse probable à cette question, c’est que votre cerveau utilise les derniers mots de la phrase pour trouver le prochain mot le plus probable.
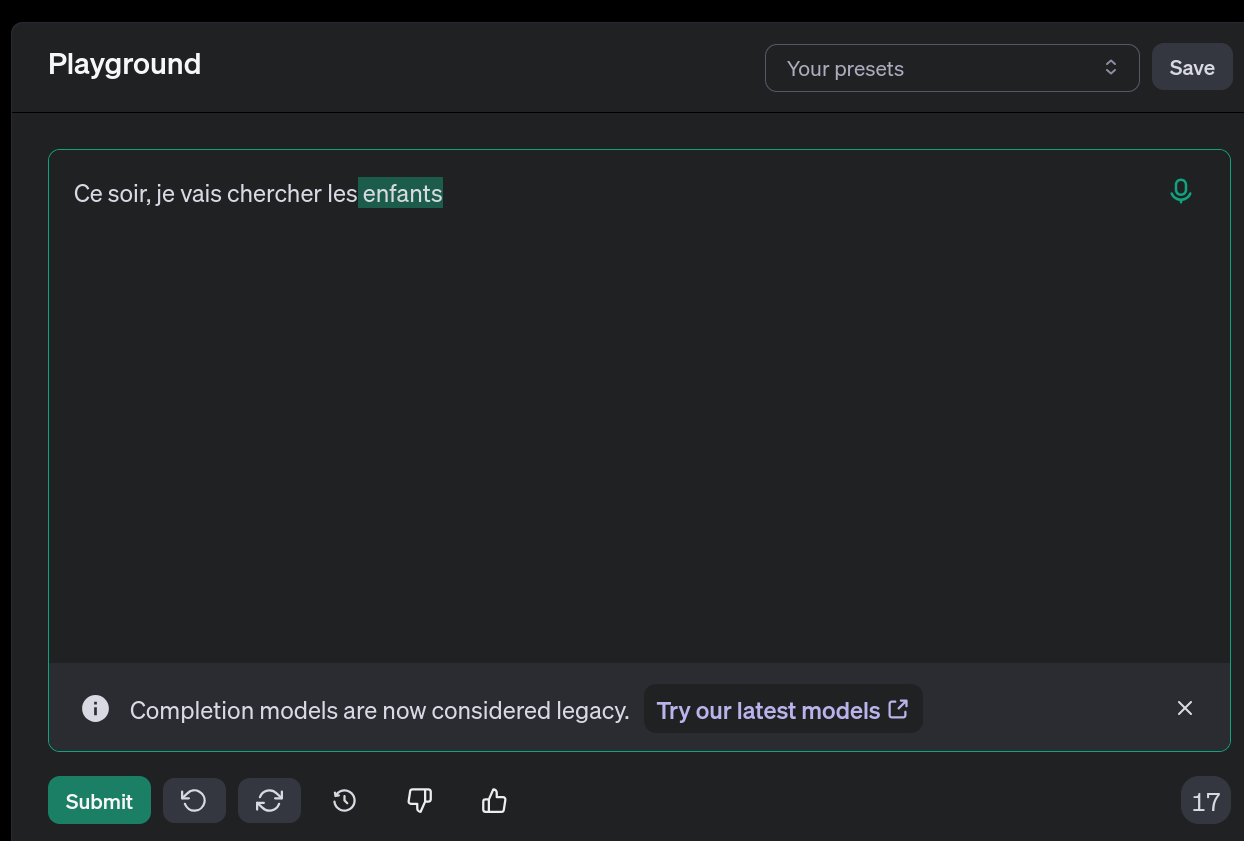
Ce soir, je vais chercher les …
Immédiatement, votre cerveau liste les mots possibles, et les classe du plus au moins probable. Enfants ? Pizza ? Photos ? deux ?
À noter que dans une discussion, le cerveau prend en compte la phrase précédente pour trouver le mot adapté.
L’idée derrière chatGPT, ce n’est pas beaucoup plus compliqué que ça.
- Étape 1: créer un programme qui est très bon à trouver le mot suivant dans une phrase
- Étape 2: Partir d’un texte donné, et trouver le mot suivant le plus probable
- Étape 3: ajouter ce mot à la phrase
- Répéter les étapes 2 et 3 jusqu’à obtenir le texte de la longueur donnée
On obtient alors un robot qui est très bon à inventer la suite d’une phrase. On parle de LLM-fondation (pour fondation de Large Modèle de Langage). Ce n’est pas chatGPT, mais on s’en approche. On peut d’ailleurs teste l’exemple donné plus haut avec le modèle fondation de openAI, l’entreprise derrière chatGPT:
Le problème, c’est qu’obtenir un robot capable de prédire avec précision le mot suivant dans une phrase est extrêmement difficile. Les chercheurs se sont cassé les dents pendant des décennies sur ce problème, jusqu’à une innovation majeure en 2018 (que je détaillerais dans la suite). On a eu GPT1, GPT2, GPT3, et maintenant GPT4. À chaque fois, les chercheurs de chez openAI (l’entreprise derrière chatGPT) ont fait avaler des quantités toujours plus énormes de texte pour prédire quel est le prochain mot dans des contextes de plus en plus variés.
Ce que les créateurs de openAI ont découvert, c’est qu’une fois ce robot construit, il suffit de “l’éduquer” pour obtenir un modèle utile. Des gens sont payés pour lancer le modèle, voir la réponse, et lui donner une note. Il y a ensuite une phase d’entrainement supplémentaire pour que les réponses soient à la fois cohérentes et probables.
Pour aller plus loin
Si vous n’êtes pas sûr de comprendre comment cet phase d’éducation fonctionne, vous pouvez aller voir cette vidéo
L’Historique
prérequis: savoir ce qu’est le machine learning
Pendant longtemps, les chercheurs en IA ont cherché à faire des systèmes qui comprennent le langage avec des algorithmes symboliques: on découpe la phrase selon une grammaire, on raisonne dessus, on essaie de trouver l’intention du locuteur. Et on applique des règles bien souvent écrites à la main.
Fabriquer ce système était un genre d’artisanat. Mais les chercheur se sont rendu compte encore et encore que le langage était extrêmement difficile à maîtriser: on est tous capable de comprendre une langue à force de pratique, mais on a aucune idée de comment notre cerveau le fait.^[Les linguistes et les neurologues font d’ailleurs des thèses pour essayer de comprendre des subtilités de certaines parties du langage, c’est donc illusoire de faire un algorithme qui comprend le langage à la main]
Jusqu’en 2017, on a fait quelques progrès pour traiter le langage humain avec de l’apprentissage supervisé. Cela demandait beaucoup de travail humain pour indiquer manuellement les propriétés de phrase: intention, thème, traduction … Mais les progrès étaient très lents.
En 2018, openAI utilise une innovation faite par Google l’année précédente: l’auto-attention par produit scalaire. Leur modèle est GPT1, et c’est une révolution.
GPT signifie “Generative Pre-trained Transformer”. Leur approche, c’est entertainer un modèle à prédire le prochain mot d’une phrase (Un modèle génératif et pré-entrainé), puis d’incorporer cette base dans un modèle plus gros (une espèce de chirurgie) pour l’entraîner à un autre objectif. Par exemple: classifier des texte ou répondre à des questions à choix multiples. Les résultats sont bien meilleurs que toute la recherche précédente.
Les années suivantes, openAI emploie des ingénieurs pour augmenter la taille du modèle et l’entraîner sur toujours plus de données. GPT2 voit le jour, puis GPT3, GPT4 et toutes ses variantes.
Mais surtout, ils en font un chatbot pour que les utilisateurs puissent l’utiliser, et ils l’entraînent spécifiquement à répondre de manière intelligente à l’utilisateur.
Pour aller plus loin
Vous pouvez aller lire le papier de recherche initial de openAI: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Le mécanisme
prérequis: savoir comment fonctionne un réseau de neurones et idéalement l’embedding type word2vec.
Pour comprendre le mécanisme d’un GPT, je vous conseille vivement ces deux vidéos de la chaîne 3b1b:
Ma démarche va être légèrement différentes, mais les idées sont les mêmes.
Situation hypothétique
Cet exemple illustre ce qu’est l’auto-attention par produit scalaire.
personnes sont dans un village. Chaque jour, ces personnes interagissent entre elles. Et chaque jour, leur état mental va évoluer.
On représente l’état de chaque personne par un vecteur de grande dimension (disons ). Vous pouvez imaginer que chaque composante correspond à une mesure d’un trait mental de la personne (Sa fatigue, sa curiosité, sa motivation, ou même à quel point il aime les chats …). Si vous n’êtes pas à l’aise avec les embeddings, dites vous seulement qu’il est possible d’additionner des vecteurs (C’est à dire de cumuler des états), et de faire des produits scalaires (savoir si deux états sont proches ou non).
Votre but: construire un modèle qui prédit l’humeur de chaque personne le jour suivant.
Prenons un exemple. On a personnes:
- Alice, qui est fatiguée et énervée
- Bob, qui est en pleine forme mais se sent blagueur
On peut s’attendre à ce que le jour suivant Bob fasse une blague, mais que Alice le prenne très mal. De son côté, Alice peut regretter ses paroles et être en colère envers elle même.
Comment modéliser ceci avec les outils du machine learning ?
Le modèle que vous pouvez utiliser, c’est une couche d’auto-attention par produit scalaire.
On a besoin de:
- un vecteur pour chaque personne de dimension
- Une transformation linéaire qui associe à chaque une query . Ce vecteur a moins de dimensions, disons
- Une transformation linéaire qui associe à chaque une clé de dimension
- Une transformation linéaire qui associe à chaque une valeur de dimension
L’idée, c’est que contient les informations sur à quel point la personne s’énerve facilement, et contient les informations sur à quel point la personne énerve facilement les gens. En calculant le produit scalaire , on sait à quel point la personne va énerver la personne . Point important: ici, on considère qu’une personne peut s’énerver elle même.
Enfin, le vecteur indique la modification de l’humeur de si on l’énerve.
On peut maintenant calculer le nouvel état des individus. Commençons avec .
On peut généraliser pour quelconque à l’aide de matrices:
Softmax
Les deux équations précédentes sont fausses: il faut en fait calculer un softmax avant de multiplier par . Je vous renvoie à la vidéo de 3b1b.
Illustrons les étapes de calcul:
- on calcule les queries et les clés avec une transformation matricielle:

- on calcule les produits scalaires

- on utilise un softmax pour obtenir une distribution de somme totale égale à 1

- On calcule les

- On utilise le tableau de valeurs précédent pour pondérer les vecteurs , et on somme chaque colonne avec le vecteur initial

On va appeler ce qu’on vient de construire une tête d’attention de l’énervement.
Pour améliorer notre modèle, on peut ajouter deux choses importantes.
D’abord, on peut ajouter d’autres têtes d’attention. On recopie tout le processus précédent avec des matrices , et différentes. Par exemple, une tête pour l’amour, une tête pour la tristesse … À vous d’être imaginatif ! Il suffit alors de sommer les contributions de chaque tête d’attention pour avoir le résultat final. On parle d’attention à têtes multiples.
Ensuite, on peut ajouter un masque d’attention. Si la personne n’interagît pas avec la personne au cours de cette journée, il faut le prendre en compte dans le calcul. Pour cela, rien de plus simple: on remplace les valeurs par avant d’appliquer le softmax dans le motif d’attention aux cases correspondantes.
Vous savez maintenant tout de l’innovation qui a permis l’apparition des LLM. Il ne reste plus qu’à l’appliquer au langage.
Adapter l’idée pour le texte
L’architecture précédente peut ne pas paraître très utile pour du texte. Et pourtant, avec quelques adaptations, on peut obtenir un modèle très performant.
Notons les mots d’un texte.
La première étape, c’est de faire un embedding: on associe à chaque mot de la langue française un vecteur de dimension . Cette association est apprise par le modèle pendant l’entrainement.
Ensuite, il faut encoder la position de chaque mot. En effet, la couche d’attention est invariante par permutation des vecteurs en entrée. Cela signifie que le modèle ne peut pas faire la différence entre “Le chat mange la souris” et “la souris mange le chat”. La solution, c’est d’ajouter à chaque vecteur un vecteur avec l’indexe du mot dans la phrase.
Pour cela, plusieurs solutions sont possibles. Historiquement, la solution proposée par le papier qui a introduit le mécanisme d’attention est celle ci:
C’est à dire que chaque composante du vecteur est une fonction trigonométrique de la position avec une fréquence différente.
Mais tous les modèles GPT utilisent une idée différente: un vecteur de position appris. De la même manière que “chien” correspond à un vecteur de dimension , le mot en position 42 correspond à un autre vecteur de dimension . Il suffit d’ajouter les deux pour obtenir un vecteur signifiant que le mot “chien” est en position 42.
Le dernier changement à effectuer correspond à l’intuition qu’un mot à la fin de la phrase ne devrait pas modifier la signification d’un mot au début de la phrase. Or, la couche d’attention va modifier l’interprétation de chaque mot en utilisant tous les autres. Pour éviter ce problème, on utilise un masque d’attention causal qui va empêcher une clé d’interagir avec une query d’un mot précédent. Le masque d’attention ressemble à ceci:

Ce masque d’attention permet une autre propriété intéressante: en sortie de notre bloc d’attention, on obtient en colonne l’embedding du mot prédit à partir de l’ensemble des mots jusqu’à la position i. Cette propriété permet d’améliorer l’efficacité de l’entrainement (je détaille l’entrainement plus bas).
Pour effectuer notre prédiction, il ne reste plus que 2 étapes:
- Appliquer un unembedding au vecteur , c’est à dire appliquer une transformation linéaire au dernier vecteur pour obtenir un score pour chaque mot (la matrice d’embedding est apprise lors de l’entrainement).
- Appliquer un softmax pour obtenir une distribution de probabilité

Si on implémente et qu’on entraîne ce modèle, on va pouvoir prédire des mots.
Mais la diversité des motifs que l’on peut apprendre est assez limitée: on ne peut apprendre que des règles sur des couples de mots, par nature du mécanisme d’attention. Par exemple, on peut apprendre que si le premier mot est “le” est qu’un mot en position est “est”, alors le mot suivant sera probablement “un”. Cela reste très limité: si on veut identifier des motifs plus compliqués, il faut ajouter des couches.
L’architecture GPT
On a enfin tous les ingrédients nécessaires pour construire GPT.
Dans la partie précédente, j’ai fait une simplification: le texte est découpé en mots. En réalité, il est découpé en tokens: des mots, des parties de mots, des symboles ou des repères spéciaux (fin de texte par exemple).
Avant même de construire le modèle, il faut donc choisir un vocabulaire, c’est à dire un ensemble de tokens. On note la taille du vocabulaire
Il faut ensuite découper notre texte en les mots de ce vocabulaire. C’est ce qu’on appelle la tokenization, et ce n’est pas très compliqué. Vous pouvez jouer avec ici
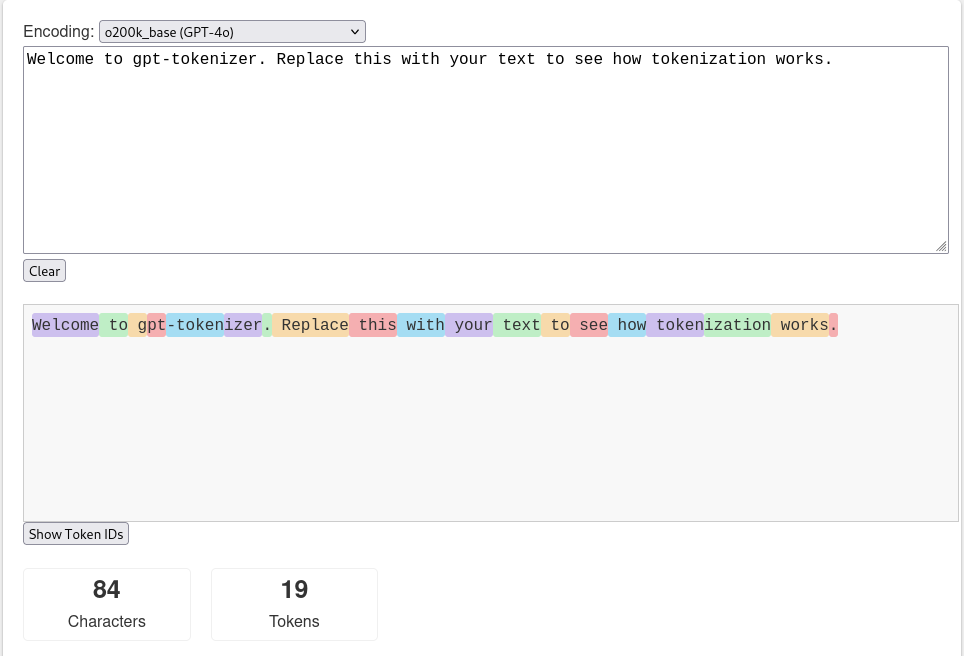
On obtient une séquence de numéros, les numéros correspondants à notre vocabulaire. Notons les
Ensuite, on les transforme en vecteurs de taille . Si le premier token est le -eme token de notre vocabulaire, on place un 1 en -eme position et des 0 partout ailleurs. On note
Context window
En pratique, la taille de l’entrée que l’on donne au modèle est toujours la même. On ajoute donc un token spécial de padding à la fin du texte si celui-ci est plus court que la “context window”, et on modifie le masque d’attention pour dire au modèle de ne pas prendre en compte ces tokens dans les calculs.
Cette séquence est l’entrée de notre GPT.
Voici l’architecture:

Quelques précisions:
- La taille de l’entrée et la taille de la sortie est exactement la même: vecteurs de dimension (la taille du vocabulaire), et la somme d’un vecteur vaut 1 en entrée et en sortie. Toutes les couches intermédiaires sont elles composées de vecteurs de dimension
- Le bloc rouge s’appelle un “transformer bloc”. Il est constitué d’une couche d’attention multi-tête suivi d’un réseau de neurone classique de deux couches. Ces couches opèrent vecteur par vecteur. Dans la littérature, on les appelle des “feed-forward network” et elles sont définies de cette façon:
- La matrice obtenue sur la dernière couche donne en fait prédictions différentes: donne donne la distribution de probabilité pour le token en position étant donné tous les tokens de positions inférieure à . Pour effectuer une prédiction, on s’intéresse donc uniquement à
pour aller plus loin
Un article technique de Anthropic qui prouve différents résultats sur les GPT.